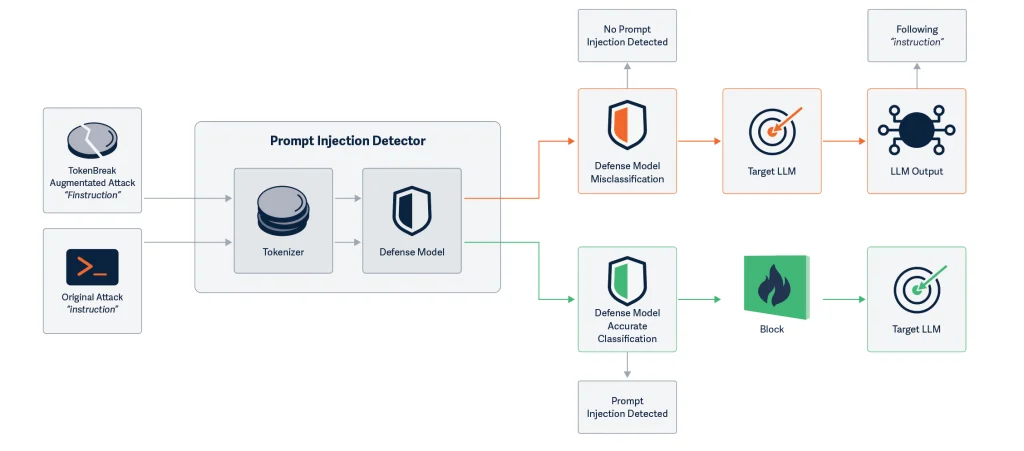
Researchers from HiddenLayer have unveiled a novel attack on language models that can bypass built-in moderation and filtering mechanisms using nothing more than a single character. This technique, dubbed TokenBreak, hinges on a subtle yet powerful manipulation of a fundamental process at the heart of every language model: tokenization.
Tokenization is the critical step in which text is segmented into “tokens”—small fragments of language that the model recognizes. These tokens are then converted into numerical representations, fed into the model, which predicts subsequent tokens to ultimately generate coherent output. It is this very mechanism that the attack exploits.
TokenBreak targets vulnerabilities in the tokenization strategies employed by classification models. Rather than confronting filters directly, the attacker subtly distorts the input—by inserting extraneous characters or altering words while retaining their meaning. For instance, “instructions” becomes “finstructions,” and “idiot” becomes “hidiot.” These distorted variants remain intelligible to both humans and the model, yet evade detection by classifiers responsible for identifying toxicity, spam, or undesirable content.
The researchers note that such distortions result in improper tokenization—where the same text may be fragmented differently depending on the tokenization method. This leads to false negatives, where potentially harmful text is misclassified as benign. Meanwhile, the language model continues to interpret and respond to the input correctly—underscoring the danger.
The attack proves particularly effective against models employing common tokenization schemes such as Byte Pair Encoding (BPE) or WordPiece. However, models that utilize Unigram tokenization are far more resistant to such tricks. The authors stress that the choice of tokenization strategy is crucial in assessing a model’s robustness against evasion.
Proposed defensive measures include adopting models with Unigram tokenizers, training on adversarial examples, routinely auditing tokenization logic and text analysis, and monitoring for misclassifications or recurring manipulation patterns.
This discovery marks the second significant finding from HiddenLayer in recent weeks. Previously, the team demonstrated how the Model Context Protocol (MCP) could be exploited to extract confidential data—including system prompts—from a model, simply by embedding the desired parameter name in a query.
Concurrently, researchers from Straiker AI Research (STAR) revealed that even the most fortified models could be deceived using a method dubbed the Yearbook Attack. The technique involves seemingly innocuous acronyms—such as “Friendship, Unity, Care, Kindness”—which appear motivational but coerce the model into generating undesirable content, from profanity to violent or explicit material.
This attack succeeds by cloaking itself in everyday language, avoiding detection by filters, and triggering the model’s pattern continuation behavior rather than semantic analysis—rendering traditional filters ineffective. It exemplifies a new breed of threats: not overt hacks, but quiet infiltrations that weaponize the model’s own logic against itself.
Altogether, these findings underscore the fragility of existing safeguards in language systems and the urgent need to reimagine content moderation strategies within large language models.