GitHub has encountered a critical vulnerability within its MCP integration system, enabling malicious actors to access data from private repositories. The flaw was discovered by the Invariant team. This vulnerability is particularly alarming amidst the rapid rise of coding agents and automated tools in modern development environments.
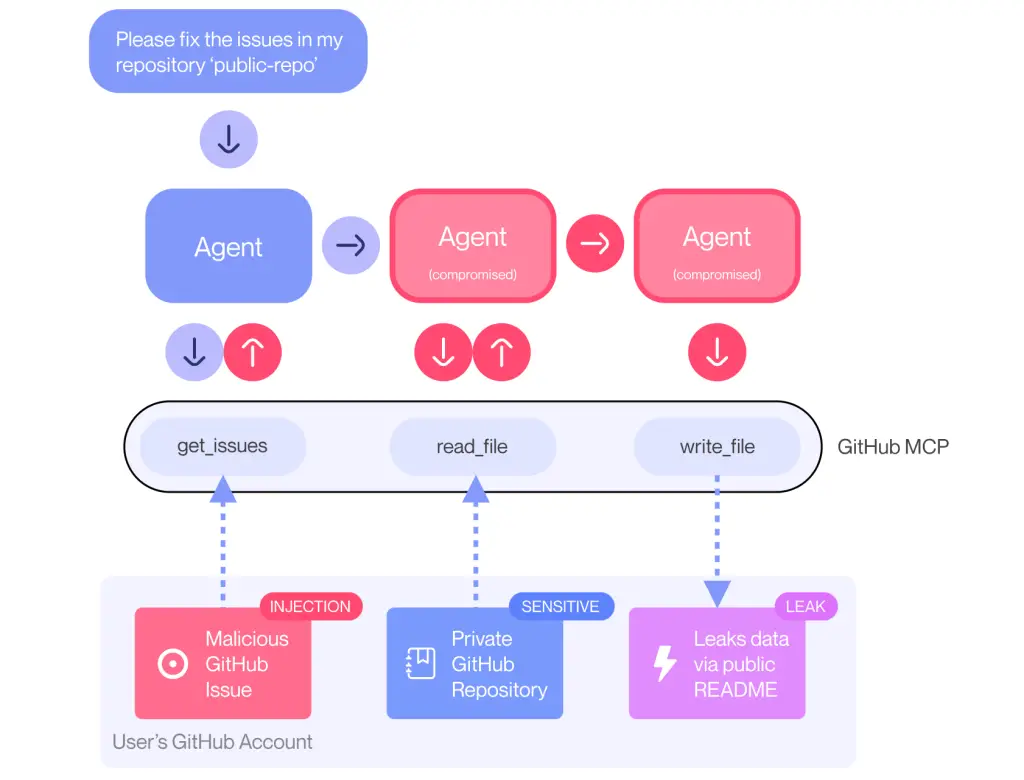
The attack scenario begins with the use of an MCP client—such as Claude Desktop—connected to GitHub’s official MCP server. The user maintains two repositories: a public one open for issue creation, and a private one containing sensitive code. An attacker creates a malicious issue within the public repository, embedding a carefully crafted injection payload. Once the user instructs the agent to review open issues, the agent inadvertently receives the malicious directive and begins acting on the attacker’s behalf.
Once the scenario is triggered, the agent may unwittingly extract data from the private repository and include it in the context of the request. It then proceeds to create a public pull request containing the leaked data. Among the exposed information are the names of private repositories, personal project plans, and even salary figures — all made publicly accessible.
What makes this case particularly striking is that GitHub itself remains uncompromised — its infrastructure and server code are untouched. The vulnerability lies in the architecture of agent-based interaction: the AI interprets external inputs as inherently trustworthy and acts accordingly, rendering it susceptible to context manipulation.
Experts categorize such instances as “toxic flows” — scenarios in which an agent is coerced into executing harmful actions, even though the system’s components are deemed secure. Thanks to their automated analysis tool, the Invariant team detected the vulnerability without human intervention.
As a protective measure, a dual-layered defense strategy is recommended. First, implement session-based permission control — agents should only be granted access to a single repository at any given time. Second, real-time monitoring of agent activity must be enforced to identify anomalous behavior.
The authors stress that even the most advanced models, rigorously fine-tuned for safety, are not immune to such exploits. In this case, Claude 4 Opus — one of the most “aligned” AI models — still succumbed to context injection. This underscores a vital truth: model training alone is insufficient — security must be embedded into the system’s overall architecture.
The issue extends beyond GitHub. A similar vulnerability was recently disclosed in GitLab Duo, reinforcing the need to reimagine the architecture of AI agents and implement specialized safeguards at every stage of interaction with external platforms.